PAW 2022
Networked and Embedded Audio Systems
CITI Lab @ INSA Lyon (France) - Dec. 3, 2022
The Programmable Audio Workshop (PAW) is a yearly one day event gathering members of the programmable audio community around scientific talks and hands-on workshops. The 2022 edition of PAW was hosted by the INRIA/INSA/GRAME-CNCM Emeraude Team at the CITI Lab of INSA Lyon (France) on December 3d, 2022. The theme of PAW in 2022 was "Networked and Embedded Audio Systems" with a strong focus on spatial audio and Field-Programmable Gate Arrays (FPGAs).
Video recordings of presentations are now available on this website in the Program Details Section.
Program Overview
Morning: Talks
| Amphithéâtre Chappe (Ground Floor) | |
|
09:00
|
Registration |
|
09:20
|
Opening Speech |
|
09:30
|
Feedback Acoustic Noise Control With Faust on FPGA: Application to Noise Reduction in Headphones Loïc Alexandre (LMFA, Éccole Centrale Lyon, France) |
|
10:00
|
Audio Processing and Streaming for the Quarantine Sessions, a Distributed Jam Session Concert Series Fernando Lopez-Lezcano (CCRMA, Stanford University, USA) |
|
10:30
|
High-Level Programming of FPGAs with FAUST for Real-Time Audio Signal Processing Applications Maxime Popoff (Emeraude Team, GRAME/INRIA/INSA Lyon, France) |
|
11:00
|
Coffee Break |
|
11:30
|
Signal Processing with Machine Learning on FPGAs Chris Kiefer (Experimental Music Techs Lab, University of Sussex, UK) |
|
12:00
|
Low Latency Interaction With Bela: What, Why and How? Adán Benito Temprano and Clemens Wegener (BELA, UK) |
|
12:30
|
Microcontroller-Based Network Client Towards Distributed Spatial Audio Thomas Rushton (Emeraude Team, GRAME/INRIA/INSA Lyon, France) |
|
13:00
|
Lunch Break |
Afternoon: Workshops
| Amphithéâtre Chappe (Ground Floor) | |
|
13:00
|
Lunch Break |
|
14:30
|
The Spatbox: an Autonomous Hardware Interface to Spatialize Sound Pierre Lecomte (LMFA, École Centrale Lyon, France) |
|
15:00
|
A Guide to Sound synthesis on Open Source FPGAs Chris Kiefer (Experimental Music Techs Lab, University of Sussex, UK) |
|
16:00
|
Coffee Break |
|
16:30
|
Faust Programming on FPGA for High Performance Real-Time Audio Signal Processing Maxime Popoff (Emeraude Team, GRAME/INRIA/INSA Lyon, France) |
|
17:30
|
Interactive Audio and Haptics On Bela Adán Benito Temprano and Clemens Wegener (BELA, UK) |
|
18:30
|
PARTAY!! |
| "Vitrine Telecom" Room (Ground Floor) | |
|
16:30-18:30
|
Musical Time With Faust Johann Philippe (GRAME-CNCM, France) |
All Day (9h - 18h30): Installations/Demos
| Location | |
| PLASMA FPGA-Based Wave Field Synthesis System Prototype | TD-C Room (1st floor) |
| PLASMA Microncontroller Network Based Wave Field Synthesis System Prototype | TD-D Room (1st floor) |
| Spatbox | TD-E Room (1st floor) |
Program Details and Videos
09:30: Loïc Alexandre — Feedback Acoustic Noise Control with Faust on FPGA: Application to Noise Reduction in Headphones
This work studies the feedback Active Noise Control (ANC) in a headphone with a digital filter implemented on a FPGA instead of an analog filter, in the context of a pedagogical practice bench. The digital approach allows greater flexibility in setting the feedback ANC filter but brings an additional latency that can compromise the ANC efficiency. The principle of feedback ANC in headphones is reviewed and the choice of a biquadratic filter as a feedback ANC filter is argued. The digital filter is programmed in the FAUST language and compiled on a FPGA platform. An experimental validation is carried out to compare the attenuation performance between the digital and analog biquadratic filters. The results show similar or even better low frequency attenuation for some configurations of the digital biquadratic filter compared to the analog filter. Finally, a digital filter cascading two biquads is studied and shows a bandwidth broadening where the ANC is effective.
10:00: Fernando Lopez-Lezcano — Audio Processing and Streaming for the Quarantine Sessions, a Distributed Jam Session Concert Series
The "Quarantine Sessions" is a geographically distributed streamed weekly concert / jam session that started after the pandemic isolated us. The core group has two members in Berlin, one in Belgium and three in California, and guests from all over the world are regularly invited to participate. We have played together more than 100 times since we started. We describe the current state of the audio streaming and signal processing signal chain and its user interface, and its evolution from its simple beginnings. It currently uses a customized Jacktrip server and software written in SuperCollider. The software spatializes the multiple client streams in 3d space using Ambisonics, locates them in a virtual space, and provides a final binaural and real-time mastered mix to the participants, and to the final streaming service being used. All the software is free, open source, and available online.
10:30: Maxime Popoff — High-Level Programming of FPGAs with FAUST for Real-Time Audio Signal Processing Applications
Field Programmable Gate Arrays (FPGAs) are very powerful embedded platforms that present significant advantages over other types of processors for real-time audio signal processing applications. Their design makes them very suitable for high parallelization and ultra fast data processing, enabling unequaled performances for audio DSP in terms of latency, throughput, sampling rate, and number of channels.
However, programming them is complex and out of reach to non-specialized engineers as well as to most people in the audio community. With the aim of having a comprehensive environment to program audio DSP on FPGAs, we present a fully open-source system that compiles any FAUST program down to FPGA hardware and up to actual sound production.
Our platform can be used for a wide range of applications and is highly configurable (i.e., sampling rate, number of channels, control interface, etc.).
11:30: Chris Kiefer — Signal Processing with Machine Learning on FPGAs
Fied Programmable Gate Arrays (FPGAs) enable us to make customised logic circuits in hardware. Recently, open source projects have made this technology more accessible for non-industrial users. FPGAs can generate and process sound with extremely high speed and low latency compared to conventional computers, although they are also limited by memory and lack of specialist processing (e.g floating point units). This talk will discuss how we can use FPGAs for signal processing, and how we can use the power of this technology to accelerate machine learning models for audio and sensor processing, considering binary represenations of sound, and binary logic networks for machine learning.
12:00: Adán Benito Temprano and Clemens Wegener — Low Latency Interaction With Bela: What, Why and How?
Bela is an open-source embedded computing platform developed for creating real-time high-quality, ultra-low latency interactive systems with audio and sensors. The Bela platform is built on top of the BeagleBone single-board computer and comprises specific hardware and a custom hard-real time audio environment based on Xenomai Linux, which is capable of submillisecond round-trip audio latencies and nearly jitter-free alignment of digital, analog and audio I/O.
In this talk, we will discuss what the sources of latency in an interactive system are, their implications and how we built our platform to tackle these.
12:30: Thomas Rushton — Microcontroller-Based Network Client Towards Distributed Spatial Audio
Rising interest in virtual and augmented reality experiences has put increased focus on research into sophisticated audio spatialisation techniques such as Wave Field Synthesis and Ambisonics. These techniques typically call for the use of large numbers of loudspeakers and a centralised digital signal processing (DSP) system; as such they are limited by the bandwidth/throughput of that system, and can be very costly, relying on specialist hardware for delivering multichannel audio output.
We propose a hardware module, based on a low-cost microcontroller, that can receive audio and control-data streams over Ethernet and deliver output to connected loudspeakers. Though reliant on a central server to send data streams to the clients, part of the DSP required to implement various spatialisation techniques takes place directly on the module, thus representing a distributed computing approach. The system is lightweight, open-source, generic in application, and scalable to large numbers of clients. In addition to spatial audio implementations, it can support and enhance -- with its accessibility and low-latency -- the kind of remote rehearsal and concert situations that rose to prominence during the COVID-19 pandemic.
14:30: Pierre Lecomte — The Spatbox: an Autonomous Hardware Interface to Spatialize Sound
The spatbox project aims at developing an autonomous hardware interface to spatialize sound and build a spatial audio soundscape on a loudspeaker array. It is a box in the shape of a synthesizer on which analog signals are entered, the buttons and sliders are used to define the sources trajectories and the analog audio outputs are directly the driving signals of the loudspeakers. Under the hood, the trajectory engine uses parametric LFOs for each spatial coordinate and the ambisonic spatialization engine is powered by ambitools. The trajectories can be visualized on an additional screen and spatial sound effects can also be integrated. A demonstration booth will be available to show you the possibilities offered by the spatbox.
15:00: Chris Kiefer — A Guide to Sound Synthesis on Open Source FPGAs
Field Programmable Gate Arrays (FPGAs) are great tools for sound synthesis, enabling us to create programmable hardware synthesisers that can run complex audio processors at high speeds. This workshop is a guide to the open source ecosystem that is growing around FPGAs, and increasing access for artists and hobbyists. We will look at the different FPGA hardware that fits into the open source toolchains, and the software environments for programming this hardware. Finally, we will explore some basic techniques for sound synthesis using binary logic, and easy ways to listen to these sounds on FPGAs, using DIY digital-to-analogue convertors.
16:30: Johann Philippe — Musical Time With Faust
Faust favorite task is to work with streams. While it could be any kind of stream, it focuses on audio streams, generating efficient and optimized code for various environments. Though, musicians will sometimes find it is difficult to compose music directly with Faust as they would do in Csound, SuperCollider, or PureData. Indeed, Faust itself may not seem particularly geared for time structures, conditional scheduling (...): it may seem to only handle sample rate time. Moreover, Faust is not a runtime environment itself, which might make musical composition even more complex.
In this workshop, we will talk about Faust and time, and show how musical structures can be built within the Functional Audio Stream. First we will make a tour of pure Faust hacking solutions to handle time. We will write some simple algorithms and describe mechanisms to control the audio flow in musical situations, trying - as often as possible - to avoid systematic audio rate control and inherent CPU waste. Then, we will start to explore Faust's virtuosity in different ecosystems - such as Csound, DAW's (...) - to see how these backends can be used to handle time elasticity with Faust. Eventually, we will certainly conclude that a strongly timed - well-designed - interpreted - open-source programming language could perfectly embrace the requirements of a musical scheduler and runtime environment for Faust.
16:30: Maxime Popoff — Faust Programming on FPGA for High Performance Real-Time Audio Signal Processing
The goal of this workshop is to discover the first audio DSP compiler targeting FPGAs using the Faust programming language. Field Programmable Gate Arrays (FPGAs) provide unparalleled audio latency and computational power, making them a better fit for audio processing than traditional CPUs. But programming them is extremely complex and out of reach to non-specialized engineers as well as to most people in the audio community. That's where Faust comes to the rescue!
By the end of the workshop, you should be able to compile your own DSP on a Xilinx FPGA using the opensource SyFaLa toolchain and control it in real-time (either with a software interface or a hardware board). You should also have a good global understanding of the possibility that such a platform has to offer for real-time audio processing.
17:30: Adán Benito Temprano and Clemens Wegener — Interactive Audio and Haptics On Bela
This hands-on workshop introduces Bela (http://bela.io), an embedded maker platform for responsive audio and sensor processing. Bela can be used to create digital musical instruments, synthesisers and other interactive projects, which can be developed in C/C++, Pure Data, Faust and Supercollider, amongst other languages. The platform features an on-board browser-based IDE and oscilloscope for getting started quickly, onboard examples and documentation, and online community resources.
This workshop will focus on prototyping low-latency audio and haptic applications based on simple concepts using C++. We will explore interactions with different sensors together with audio exciters (transducers).
Bela kits, breadboards, sensors and electronics will be provided for use during the workshop. Participants should bring their own laptop (no specific OS or software required other than a browser) with one free USB-A available to connect the Bela kit and a pair of headphones.
About the Speakers
Loïc Alexandre
Loïc Alexandre is a PhD candidate at LMFA (Laboratoire de Mécanique des Fluides et d'Acoustique) working on active noise control and sound field synthesis using high order ambisonics. After studying acoustics at the university of Le Mans and then at Ecole centrale de Lyon, he joined the FAST ANR project (GRAME, CITI Lab, LMFA) through his PhD thesis. In the context of this project, his work active noise control in headphones using Faust has already been shared during the IFC22 conference.
Fernando Lopez-Lezcano
Fernando Lopez-Lezcano was given a choice of instruments when he was a kid and liked the piano best. His dad was an engineer and philosopher, his mother loved biology, music and the arts. He studied both music and engineering, and tries to keep them balanced. He has been working at CCRMA since 1993. He throws computers, software algorithms, engineering and sound into a blender and serves the result with ice in tall glasses, and over many speakers. He can hack Linux for a living, and sometimes he likes to pretend he can still play the piano. He built El Dinosaurio (an analog modular synth) from scratch 40 years ago, and it still sings its modular songs. He also loves to distill music from pure software. His modular herd, which he is still trying to tame, grew recently, and includes El Dinosaurio, a Noise Toaster, an ARP 2600 clone and the big Applesauce Mark V eurorack (and a fake piano!). He was the Edgard-Varèse Guest Professor at TU Berlin in 2008.
Maxime Popoff
Maxime Popoff is a PhD candidate at INSA Lyon (Institut National des Sciences Appliquées), specialized in electronic and embedded systems. He studied at Grenoble-INP and worked as an engineer at the CEA Grenoble and then at Inria where he joined the Emeraude team (INSA Lyon, Inria, GRAME) in 2020. His research work focuses on embedded audio platforms and their programming.
Chris Kiefer
Chris Kiefer is a computer-musician, musical instrument designer and Lecturer in Music Technology at the University of Sussex, in the Experimental Music Technologies Lab. As a live coder he performs under the name 'Luuma'. He plays an augmented self-resonating cello as half of improv-duo Feeback Cell, and with the feedback-drone-quartet 'Brain Dead Ensemble'. His research explores interaction design, complex systems and machine learning in musical instruments.
Adán Benito Temprano
Adan Benito is currently pursuing his PhD within the AI + Music programme at Queen Mary University of London in the Centre for Digital Music (C4DM). His research interests focus on the possibilities of gesture analysis and disambiguation on guitar performance for the design of expressive instrument augmentations. Adan holds an MSc on Sound and Music Computing from Queen Mary University of London, and a Telecommunications Engineering Degree and an MSc in Radio Communications from University of Cantabria. Since 2018 he has been one of the core developers behind Bela (bela.io). Besides that, he has a passion for all things related to guitar experimentation, from technology to techniques and repertoire.
Clemens Wegener
Clemens Wegener holds a Master’s degree in Computer Science and Media from Bauhaus-Universität Weimar. He completed a Bachelor’s degree in musicology at the Hochschule für Musik Franz Liszt Weimar. He works as a research assistant and lecturer in Interface Design at Bauhaus-UniAdan Benito is currently pursuing his PhD within the AI + Music programme at Queen Mary University of London in the Centre for Digital Music (C4DM). His research interests focus on the possibilities of gesture analysis and disambiguation on guitar performance for the design of expressive instrument augmentations. Adan holds an MSc on Sound and Music Computing from Queen Mary University of London, and a Telecommunications Engineering Degree and an MSc in Radio Communications from University of Cantabria. Since 2018 he has been one of the core developers behind Bela (bela.io). Besides that, he has a passion for all things related to guitar experimentation, from technology to techniques and repertoire.versität Weimar. His research focuses on digital and analog sound synthesis as well as musical interfaces. With a background of music production and live performance he can establish connections between classical musical instruments and modern technologies. He is co-founder of the Center for Haptic Audio Interaction Research (CHAIR) and develops electronic musical instruments as well as software with them. CHAIR has an ongoing collaboration with Bela.
Thomas Rushton
Thomas Rushton is a student on the Sound and Music Computing MSc program at Aalborg University in Copenhagen. Currently an intern on Inria's EMERAUDE (Embedded Programmable Audio Systems) team, his work on digital musical instrument design has appeared in the proceedings of 2022's SMC conference; he was also a contributor to the 2022 Interactive Sonification workshop, presenting his work on interactive auditory biofeedback for runners.
Pierre Lecomte
Pierre Lecomte is an associate at the University of Lyon 1. His research includes spatial audio, a field in which he is active since 2013. In this domain, he develops and maintains a suite of tools written mainly in Faust language for the synthesis of sound fields with Ambisonics: ambitools. He has also realized several spherical loudspeaker arrays: the SpherBedevs and spherical microphone arrays. Recently he is interested in active spatial sound control and participates in the FAST ANR project with the INRIA EMERAUDE team and the GRAME.
Johann Philippe
Electroacoustic music composer and computer music designer at IRCAM, Johann Philippe focuses his artistic research on creative coding and electronic performance. Persuaded that musical adventure is something to be shared, he also works with the transmission department of GRAME. During holidays, he contributes to the development of open-source musical technologies ecosystems such as Csound, Faust, as well as his own tools.
Coming to PAW + Contact
Participants must register online: PAW 2022 REGISTRATION.
Registration is free within the limit of available seats.
PAW is taking place at CITI Lab this year which is located on the INSA Lyon Campus at the following address: CITI Lab, 6 avenue des arts, 69100 Villeurbanne, France.
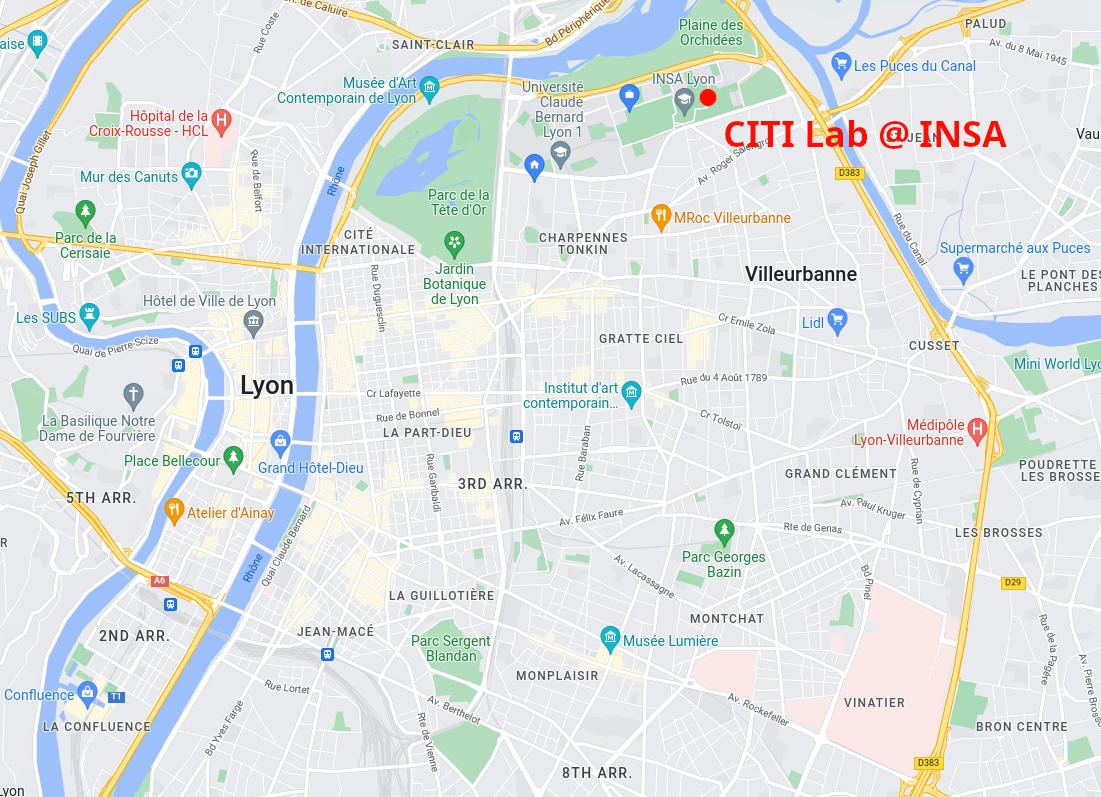
The easiest way to get to CITI from the city center is to take the tramway T1 or T4 and stop at "La Doua Gaston Berger." Cycling is also a good solution :). The closest hotels are in the Charpennes neighborhood.
Feel free to send your questions to paw_at_grame_dot_fr.
Some suggestions for getting lunch:
- Ninkasi la Doua: https://goo.gl/maps/D1ec2JEXqSZVX1Uj6
- Univers Café: https://goo.gl/maps/ZYGKrmGzSPpQSuff6
- L'atelier Salengro: https://goo.gl/maps/RKEnYXLx7Bd8aWhA9 (bakery, cheap option)